![[SDXL Turbo] 爆速画像生成AIで柴犬ジェネレーターを作ってみました](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1728065979/user-gen-eyecatch/atthnqkssrhtihoopg9o.jpg)
[SDXL Turbo] 爆速画像生成AIで柴犬ジェネレーターを作ってみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
テキストから画像が生成できるAIは、イメージを言葉で伝えるだけで、高品質な画像が生成できることから、様々なシーンでの活用が検討されていると思います。
しかし、テキストプロンプトのみで、思い通りの画像を生成するのは、実は、結構難しい作業だったりします。「なかなか、思った通りの絵にならない」というところです。
そして、その解決策の1つが、とにかく多数の画像を生成して、その中から、イメージにマッチするものを選ぶというものです。
今回は、Stability AIの SDXL Turboを使用して、この作業を試してみました。
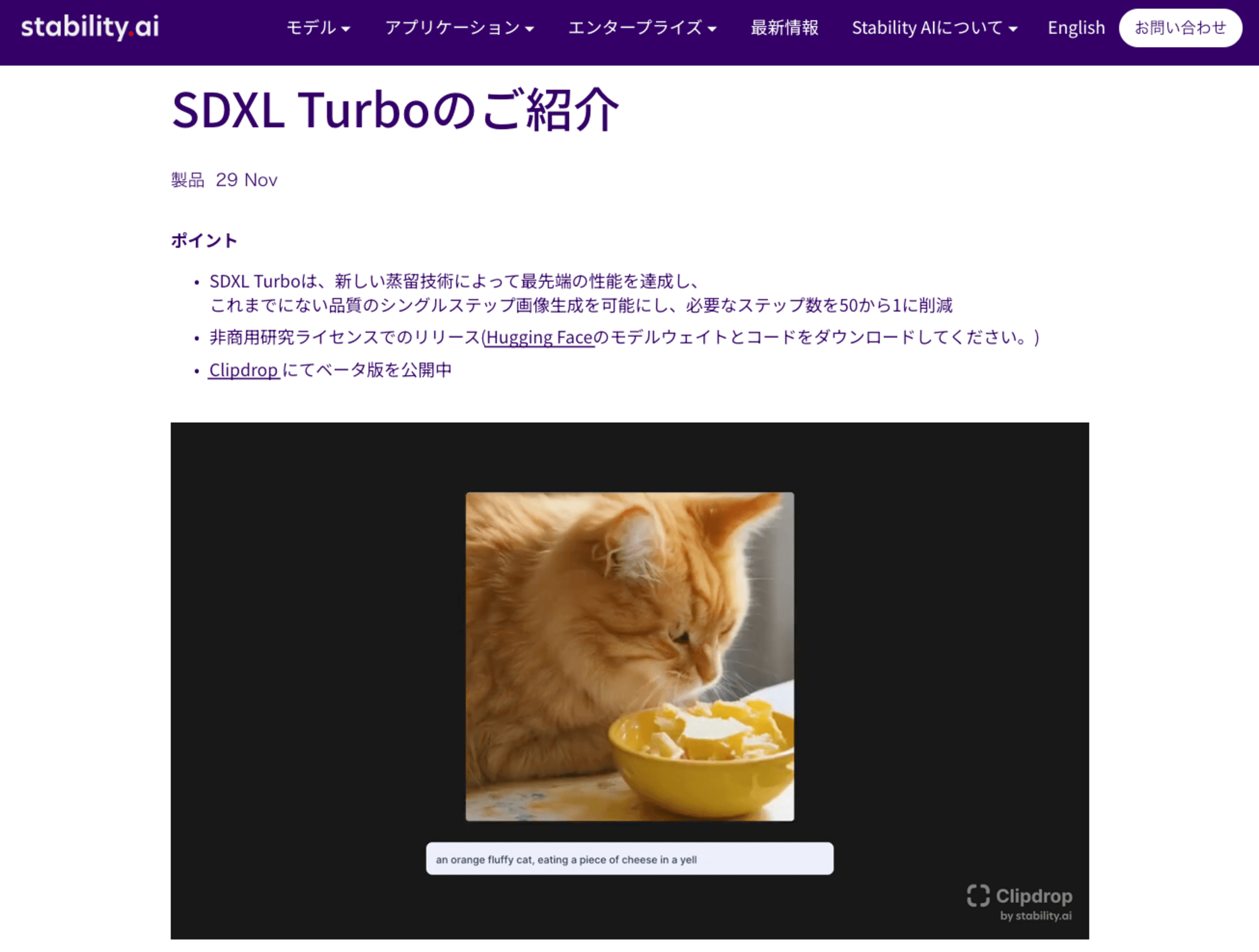
SDXL Turbo は、敵対的拡散蒸留 Adversarial Diffusion Distillation:ADD と呼ばれる新しい蒸留技術に基づき、たったの1ステップで、超高速に画像を出力できます。
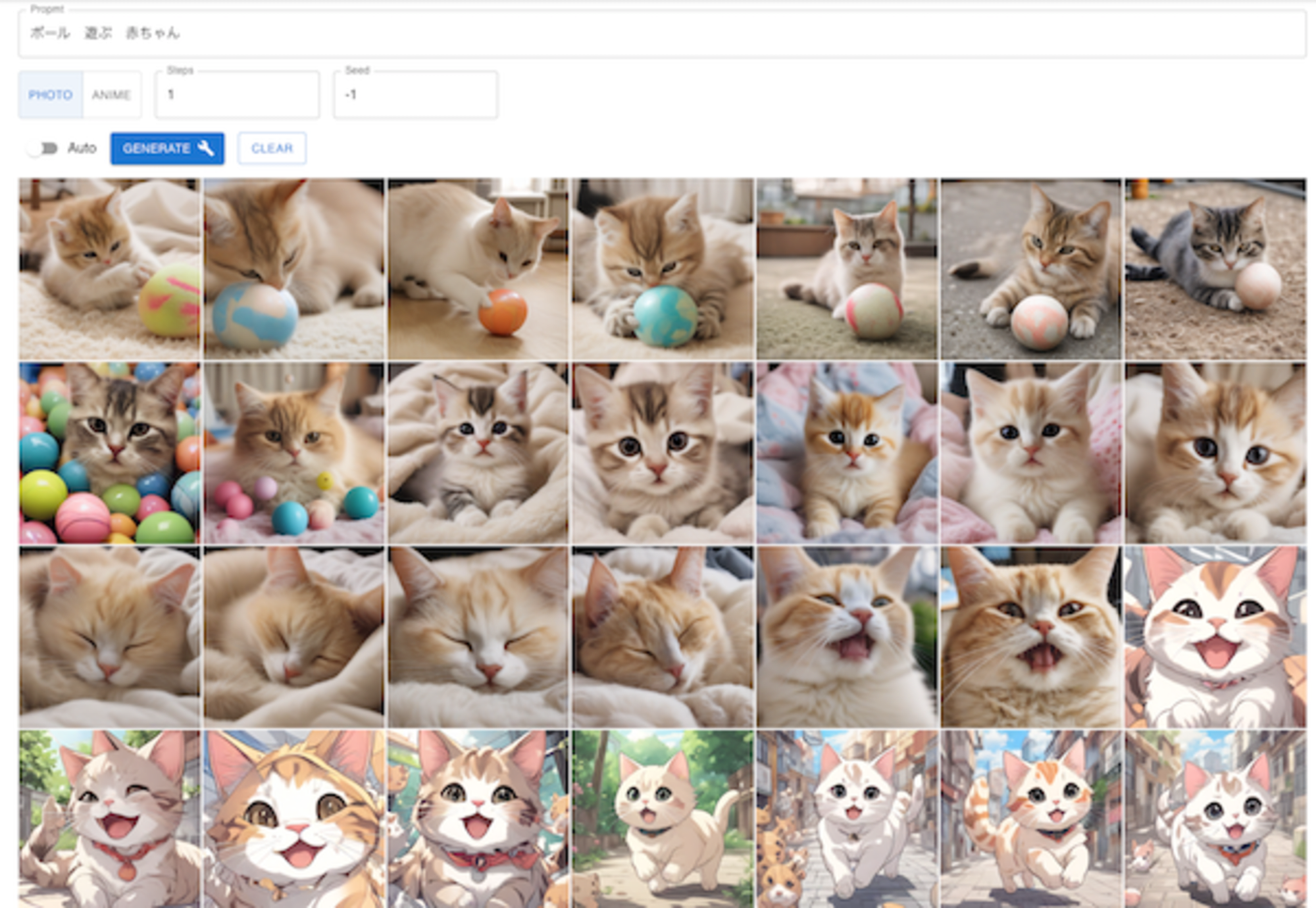
最初に、試してみた「柴犬ジェネレーター」を見てやってください。
プロンプトには、デフォルトで「柴犬」が設定されており、入力したテキスト及び、「ANIME」「PHOTO」の選択が、プロンプトに付加され、モデルに送られています。
GENERATEボタンを押す度に、1枚ずつ画像が生成されます。そして、Auto を ON にすることで、勝手にGENERATEボタンが次々押されるようになります。
注意:SDXL Turboの商用利用は、https://stability.ai/license を参照ください。
2 構成
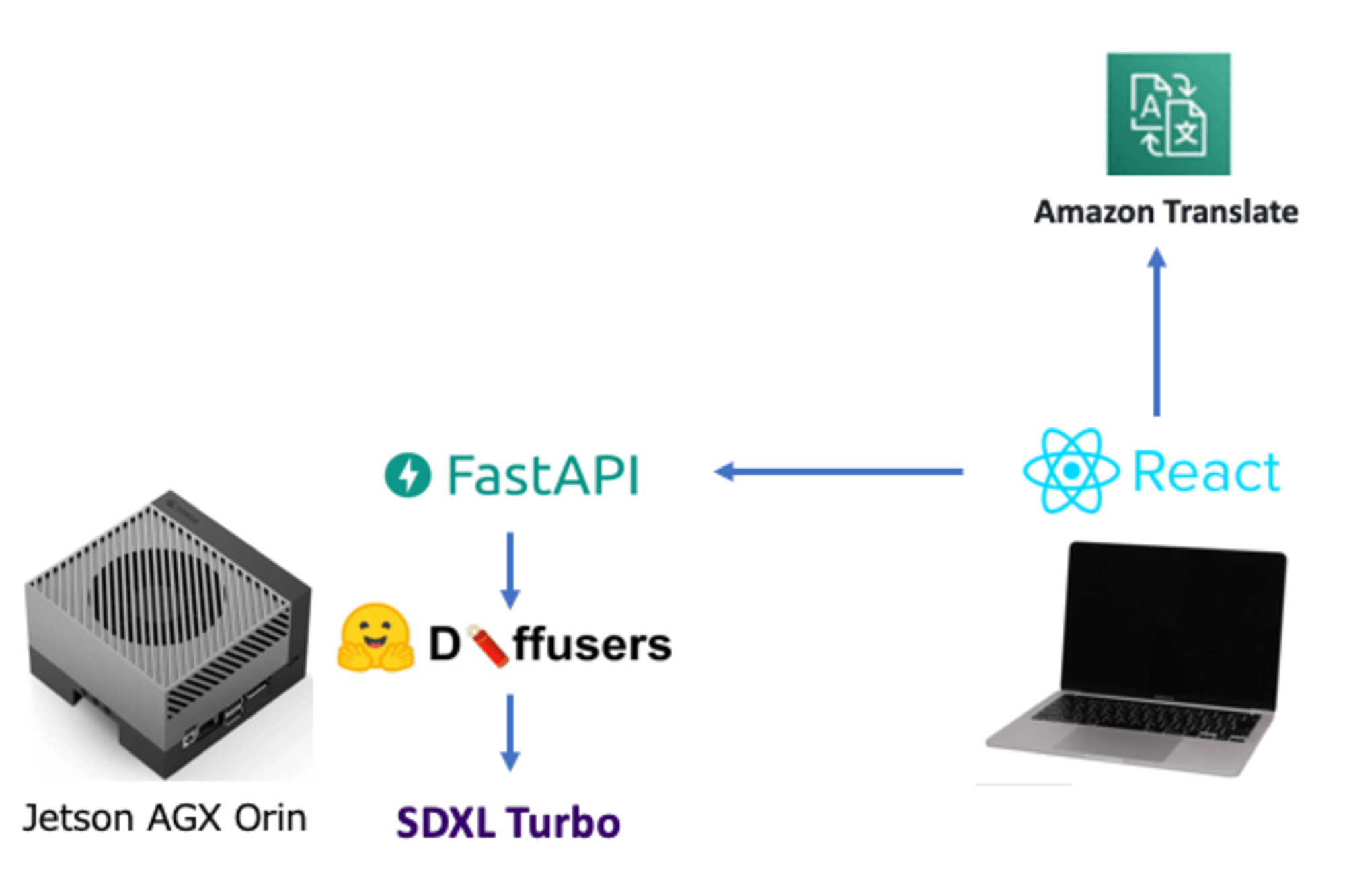
試してみた、SDXL Turbo の利用形態は、おおむね以下のとおりです。
- 画像生成は、Jetson AGX Orinで行っています
- SDXL Turboは、HuggingFace Diffusersから利用しています
- FastAPIでPythonによるRestAPIを構成し、画像生成等を行っています
- ブラウザのUIは、ローカルでホストしているReactで動作しています
- プロンプト入力は、日本語になっていますが、APIに送る前に、Amazon Translateで英語に翻訳しています
3 HuggingFace Diffusers
モデルの実行には、HuggingFace の Diffusers を使用させていただきました。
Diffusersは、トレーニング済みの拡散モデルを扱うライブラリで、推論のためのパイプラインを数行のコードで構成できます。
AutoPipelineForText2Imageで、Hugging Face Hub の任意のチェックポイントを使用できるので、ここで SDXL Turboを指定することでモデルをダウンロードしています。
また、高速化のため、精度を落としましたが(torch_dtype=torch.float16)、生成される画像は、殆どかわりませんでした。
SDXL Turboは、通常の StableDeffusion のモデルとは、パラメータが違い、ネガティブプロンプトなどが無いことに注意が必要です。
from diffusers import AutoPipelineForText2Image
pipe = AutoPipelineForText2Image.from_pretrained(
"stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16"
)
pipe.to("cuda")
seed = random.randint(1, 10000)
generator = torch.Generator("cuda").manual_seed(seed)
image = pipe(
prompt="prompt",
num_inference_steps=1,
generator=generator,
guidance_scale=0.0,
).images[0]
image.save(output_filename)
4 FastAPI
APIを構成するために、FastAPIを使用しています。
/generateにPOSTを受けると、指定されたパラメータに基づいて、Diffusersのパイプラインで画像を生成しています。
class Params(BaseModel):
prompt: str
steps: int
seed: int
# 画像生成のエンドポイント
@app.post("/generate")
async def generate(params: Params):
prompt = params.prompt
timestamp = int(time.time() * 1000)
output_filename = f"{BASE_PATH}/{OUTPUT_PATH}/{timestamp}.png"
seed = random.randint(1, 10000) if params.seed == -1 else params.seed
steps = params.steps
# 画像を生成
generate_data(
pipe,
prompt,
seed,
steps,
output_filename,
)
# 生成された画像のURLを返す
url_path = f"/{OUTPUT_PATH}/{timestamp}.png"
return {"url": url_path}
生成された画像は、ファイル名を指定して、/output からGETで取得するようになっています。
# 指定されたファイル名の出力ファイルを取得するエンドポイント
@app.get("/output/{filename}")
async def get_output_file(filename):
file_path = f"{BASE_PATH}/{OUTPUT_PATH}/{filename}"
if os.path.exists(file_path):
return FileResponse(file_path, media_type="image/png")
else:
return {"error": "File not found"}
全てのコードです。
app.py
5 Docker
Jetson AGX Orin上では、Dockerで環境を構築しています。
JetPack6.1用のベースイメージとして、dustynv/jetson-inference:r36.3.0を使用することで、Pytorch等の環境構築が完了できます。
環境変数「XDG_CACHE_HOME」は、Diffusersがモデルをダウンロードするディレクトリをマウントしたディスクにするために設定しています。
FROM dustynv/jetson-inference:r36.3.0
RUN pip3 install diffusers==0.30.3 transformers==4.45.1 ftfy accelerate fastapi uvicorn
COPY api.py start.sh /
RUN chmod 755 /start.sh
# diffusersでダウンロードされるモデルをマウントしたディスクにするためキャッシュ指定設定する
ENV XDG_CACHE_HOME="/data"
CMD ["/bin/bash","/start.sh"]
# python3 --version
Python 3.10.12
# python3 -c "import torch;print(torch.__version__)"
2.2.0
# python3 -c "import torch;print(torch.cuda.is_available())"
True
6 React
Reactで作成されている画面の構成です。
- ① Promptに追加情報を日本語で入力します
- ② PHOTO ANIME 写真調かアニメ調かを選択できます
- ③ Step 生成ステップで1以上の数値を指定します
- ④ Seed シード値 同じ数値を指定すると同じ画像が生成されます -1で、ランダム指定となります
- ⑤ Auto このスイッチをONにすると、自動的に次々と生成されます
- ⑥ GENERATE ボタンを押すと1枚の画像が生成されます
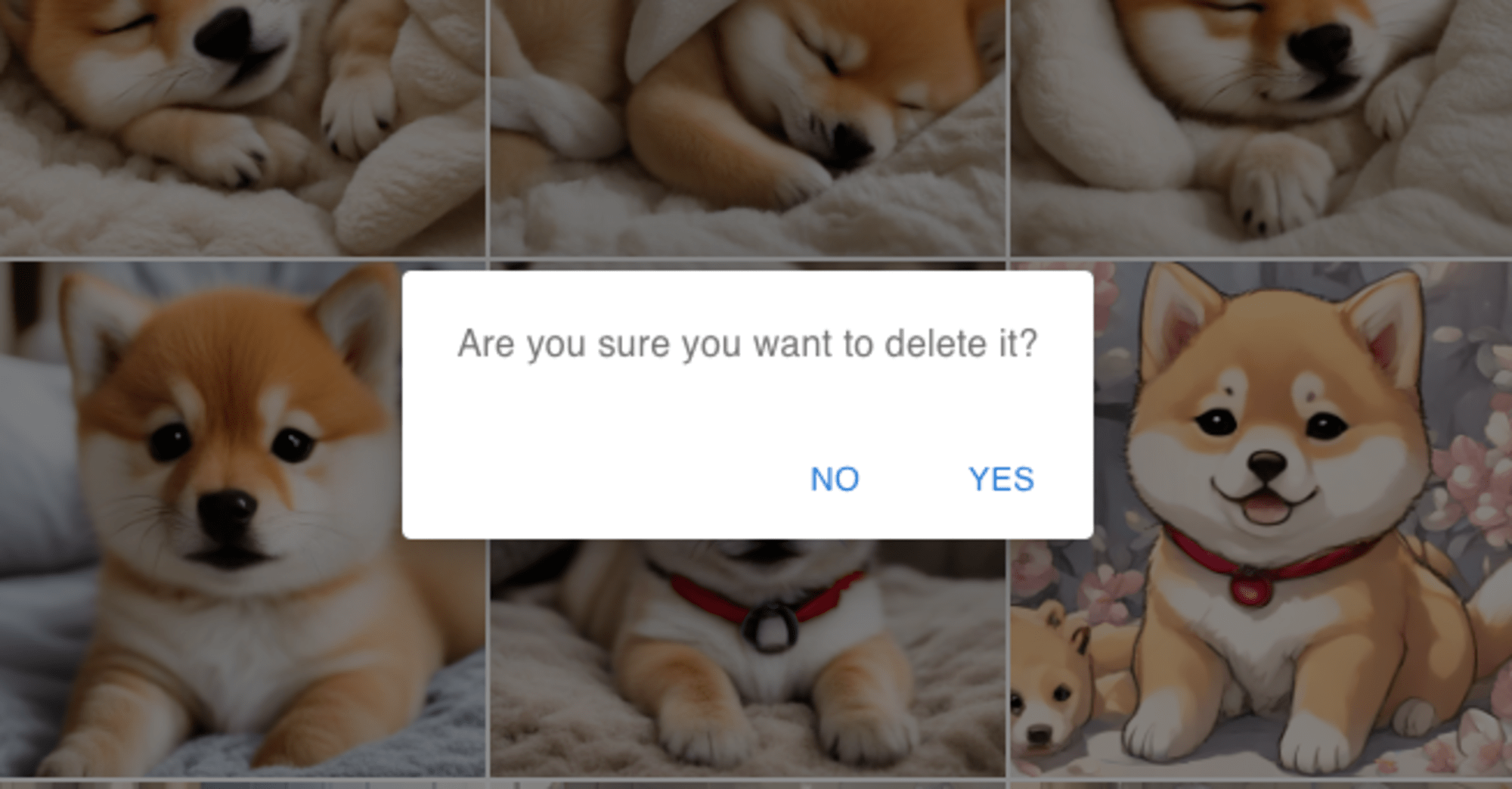
- ⑦ CLEAR 画像を削除します
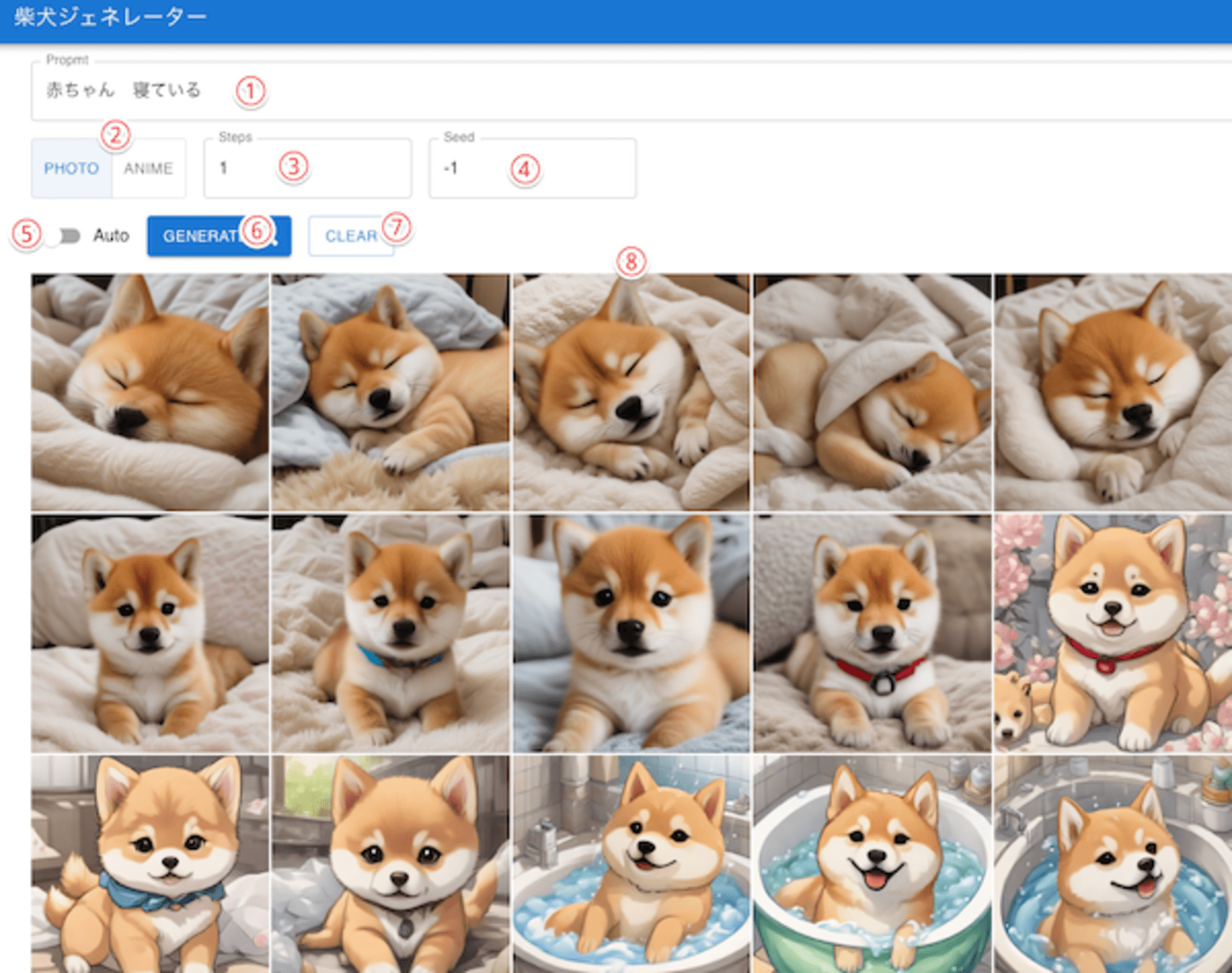
- 画像を選択すると、拡大表示することができます


- CLEARボタンを押すと表示される確認ダイアログで「YES」を押すと、すべての画像が削除されます
コードです。
App.tsx
ConfirmView.tsx
InputView.tsx
ModalView.tsx
7 最後に
今回は、画像生成AIを使用して、多数の画像を生成し、その中から「イメージに合うものを探す」という方法を試してみました。
画像生成は、ローカルにあるJetson(GPU)で生成しているので、1日中何枚生成しても、電気代程度の費用で済むと思われます。
「Shiba Dog」を書き換えると、猫ジェネレータにもなります。